Leveraging Passage Retrieval with Generative Models for open-domain Question Answering
25th July 2020
keywords: generative model, question answering, passage retrieval
This post will walk through a paper by Facebook AI Research and Inria Paris: [arXiv]
This is one of my favorite papers as it shows how instead of having a generative model with large number of parameters, you can augment a relatively smaller generative model with information retrieval approaches and still achieving required performance.
This paper presents an approach to open-domain question answering that relies on retrieving support passages before processing them with a generative model. Generative models for open-domain question answering have proven to be competitive, without resotring to external knowledge source. However, that comes with a tradeoff in number of model parameters in Generative models. This paper presents how Generative model can benefit from retrieving passages and how its performance increases by increasing number of passages retrieved. Authors have obtained state-of-the-art results on Natural Questions and TriviaQA open benchmarks. This indicates that Generative models are good at aggregating evidence from multiple retrieved passages.
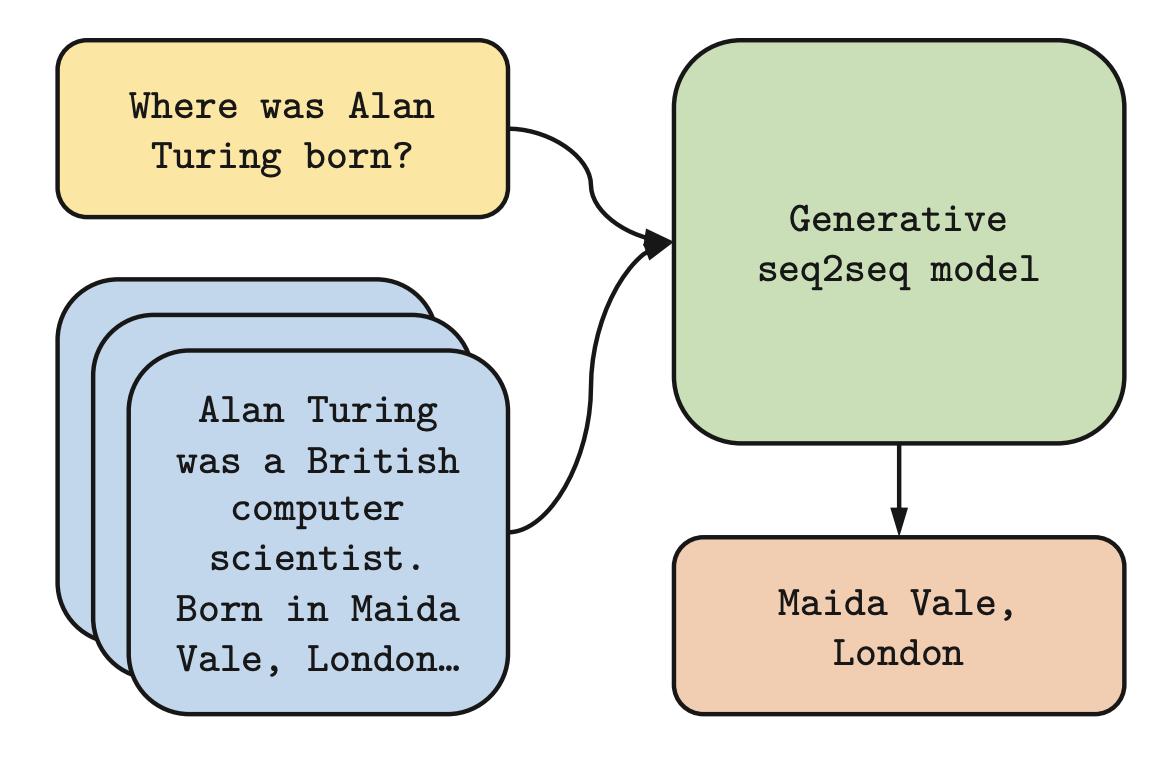
Figure shows a simple approach to open-domain question answering. Firstly, supporting text passages are retrieved from external source of knowledge such as Wikipedia. Then a generative encoder-decoder model produces the answer, conditioned on the question and the retrieved passages. This approach scales well with number of retrieved passages.
Background of passage retrieval and generative question answering
Generative modeling for open-domain question answering has been a research area continuously being explored. Building langage models with billions of parameters, where all the information is stored in model parameters have been in the leaderboards for several benchmarks. The major concern with such models is the model size. The training and inference with such huge models is expensive. This paper presents an alternative to building such large models and still getting similar benchmark results just by using external source of knowledge.
We have seen Question Answering systems being evolved when it comes to passage retrieval - initially using non-parameterized models based on TF-IDF, by leveraging additional information from Wikipedia graphs (Asai et al. 2020), and by using dense representations and approximate nearest neighbors. The benefit of using passage retrieval using dense representations is that such models can be trained using weak supervision (Karpukhin et al. 2020).
We have seen the use of Generative models for question answering where the answer does not correspond to a span in the passage. T5 model by Raffel et al. (2019) is a perfect example of how competitive generative models can be for reading comprehension tasks such as SQuAD. There are models that use large scale pretrained generative models with or without any kind of augmentation to the model like Roberts et al.(2020) and Min et al.(2020) and Lewis et al.(2020). The key differentiator of this research work with prior work is that- the way the retrieved passages are processed by the generative model is diffferent in this piece of work - as we will see in sections ahead.
Approach
TL;DR
- The approach presented in this paper consists of two steps: firstly retrieving support passages using sparse or dense representations; and then a Seq2Seq model generating the answer, taking question and the retrieved supporting passages as input.
- This approach sets state-of-the-art results for TriviaQA and NaturalQuestions benchmark.
- The performance of this approach improves with number of supporting passages retrieved, indicating that Seq2Seq model is able to give better answers by combining evidence from retrieved passages.
Passage Retrieval
As we have seen in emerging trend that when we have a reader model that detects the span in passage as answer - it is not possible to apply the reader model to all the passages in system - as it will be super expensive computationally. Thus, any open-domain Question-Answering sysmtem needs to include an efficient retriever component that can select a small set of relevant passages which can be fed to the reader model.
Authors considered two approaches here: BM25 and Dense Passage Retrieval (Karpukhin et al. 2020).
- BM25
- Passages are represented as bag of words and ranking function is based on term and inverse document frequences. Default implementation from Apache Lucene was used for this.
- Dense Passage Retrieval
- Passages and questions are represented as dense vectors whose representation is obtained by using two separate BERT models - one for encoding passages and other to encode only questions. The ranking function in this case is the dot product between query and passage vectors. Retrieval of passages in this case is done using approximate nearest neighbors with Facebook's FAISS library.
Let's have a closer look at what is Dense Passage Retriever(DPR) and how it works.
Given a collection of M text passages, the goal of DPR is to index all the passages in a low dimensional continuous space such that it can retrieve efficiently the top-k passages relevant to the input question for the reader at run-time. Here M can be very large( in the order of millions of passages) and k is reletively small ~ 20-100.
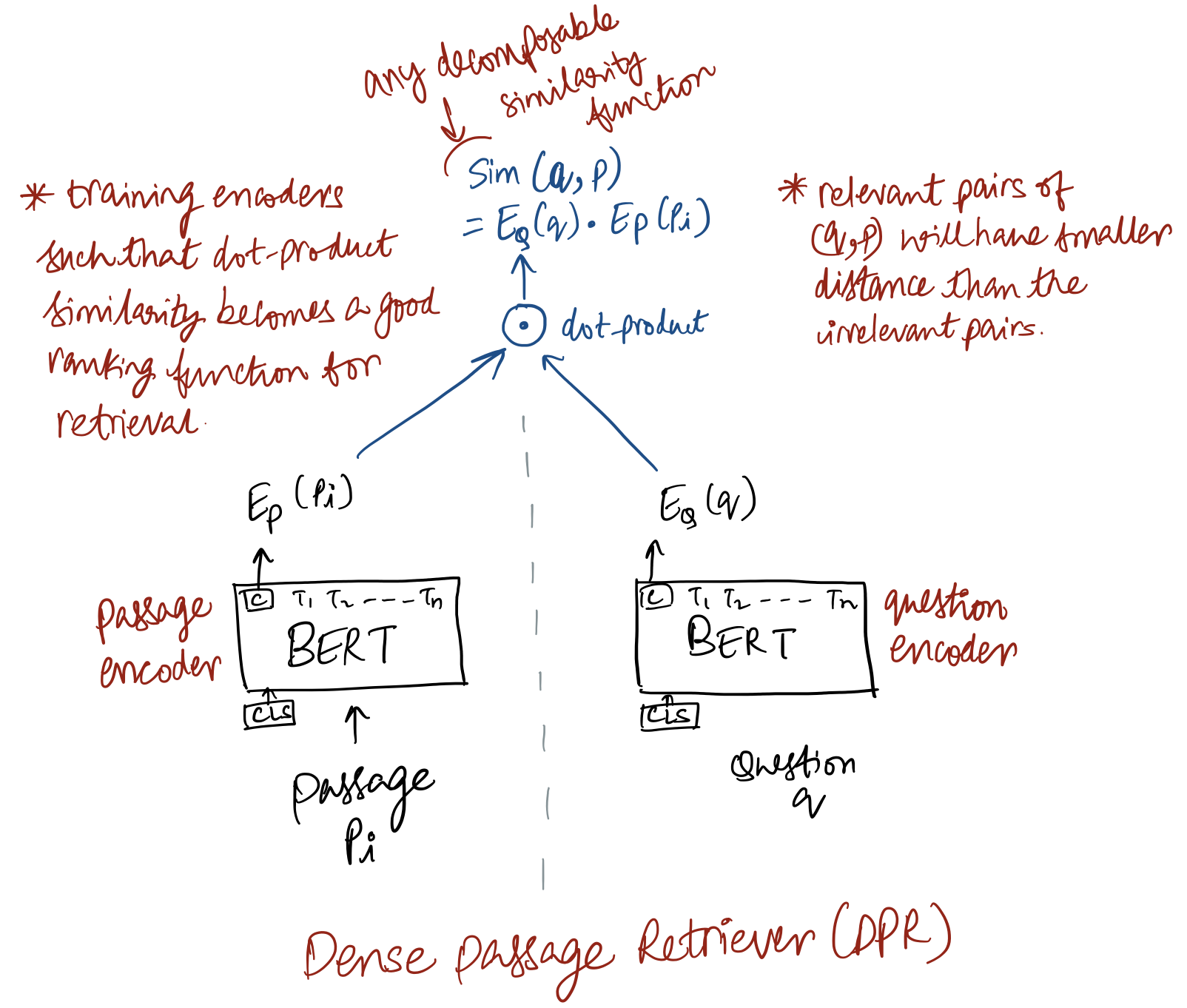
You can see the design details of DPR in the figure above. Key points:
- Two indepedent BERT networks are used as dense encoders for passage as well as question. Passage encoder maps any test passage to a d-dimensional vector. Such vectors are used to build an index that is used for retrieval.
- Training of DPR involves training the encoders such that dot-product similarity becomes a good ranking function for retrieval. At inference time, the question encoder encodes the input question to a d-dimensional vector and this encoding is used to retrieve k passags of which vectors are the closest to the question vector. The similarity function used in DPR is dot-product, but any decomposable similarity function can be used - such as some transformations of Euclidean distance.
- For indexing and retrieval, FAISS (Johnson et al. 2017) library is used - as it supports efficient similarity search and clustering of dense vectors applicable to billions of vectors.
Generative model for Answer Generation
The generative model in this approach is based on a Seq2Seq network pretrained on unsupervised data - such as BART or T5. T5 (Text-to-Text Transformer) model is a model where all the tasks are modeled using Encoder-Decoder architecture. The architecture presented in this paper is very similar to The Transformers (Vaswani et al. 2017), but with a small variation as you will see as we proceed. Below shown is the standard Transformer architecture by Vaswani et al:
![]()
T5 Model takes input: Each of the passage retrieved by DPR is fed to the Encoder in Transformer, alongwith the question and title as shown in the figure below:
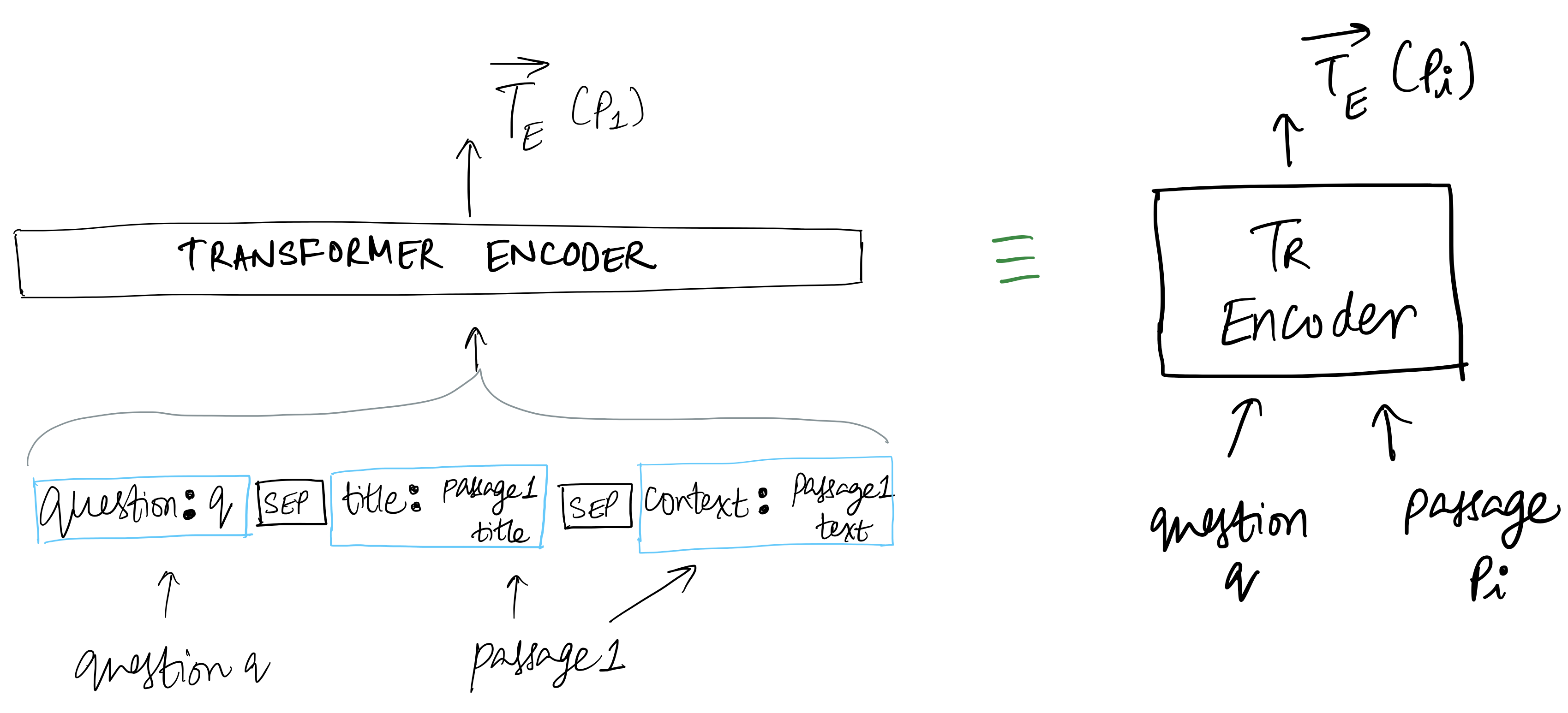
- Encoder
- Question + retrieved support passages -> Question is prefixed with "question:", title of passage is prefixed with "title:" and each passage is prefixed with "context:". Each passage and its title are concatenated with question and fed into Encoder.
- Decoder
- Decoder performs attention over the concatenation of the resulting representations of all retrieved passages. This approach is referred as Fusion-in-Decoder as model performs evidence fusion in the decoder only.
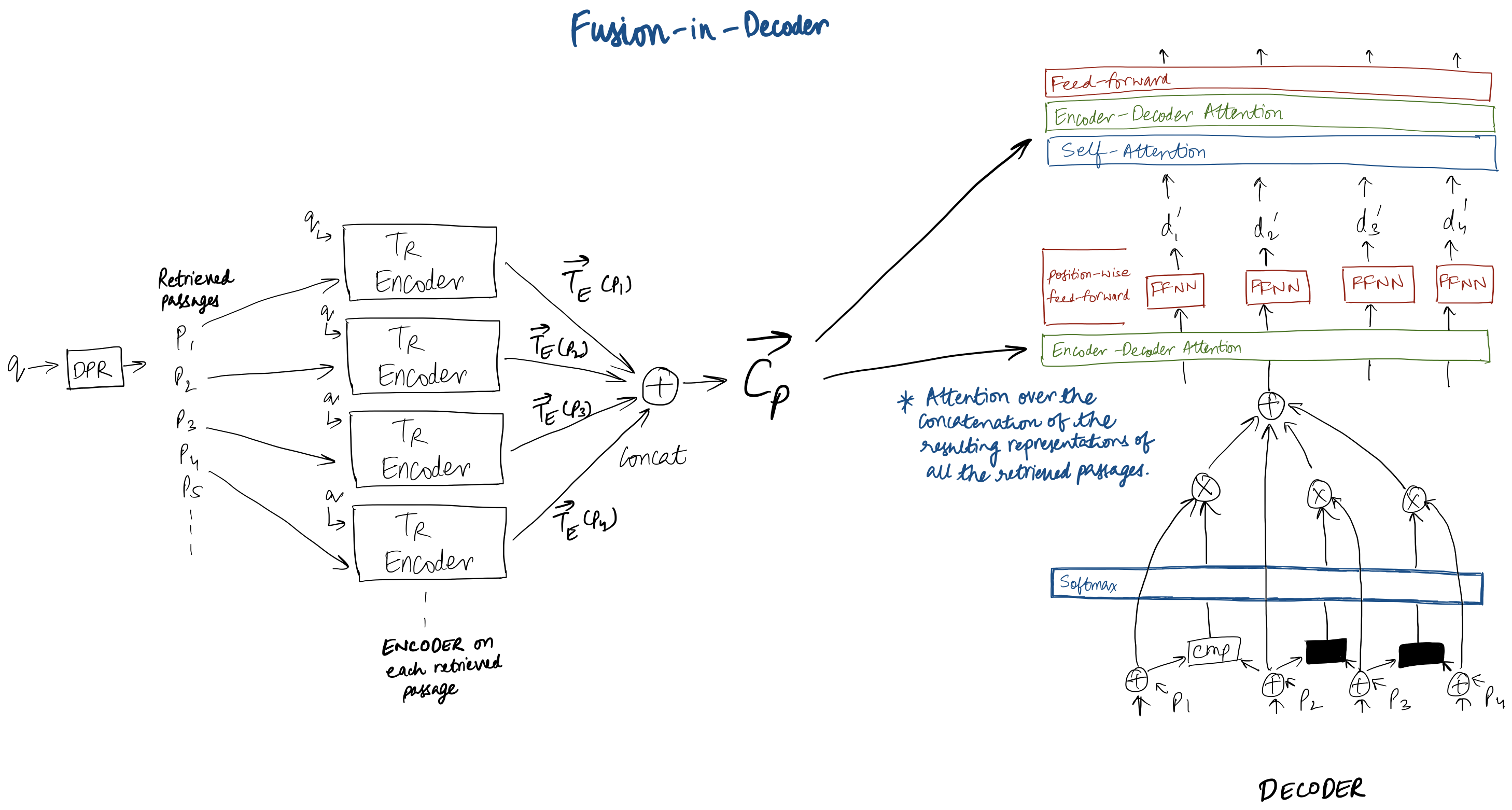
As you can see in figure above, for a given question, Dense Passage Retrieval(DPR) retrieves say k pasages; Each passage is passed through Transformer encoder (where question, passage title, passage text are prefixed and fed as shown in figure above). The resulting representation of each retrieved passage is concatenated and the resulting vector is used on decoding side for attention. i.e. Decoder will attend to this vector while decoding. This joint processing of passages in the decoder allows to better aggregate the evidence from multiple passages. Processing passages independently in the encoder allows to scale to large number of contexts, as it only performs self attention over one context at a time. Thus, the computation time is linear in number of passages.
Metrics, Experiments & Results
The metric reported in this paper is EM(ExactMatch) as introduced by Rajpurkar et al.(2016). A generated answer is considered correct if it matches any answer of the list of acceptable answers after normalization. This normalization step consists in lowercasing and removing articles, punctuation and duplicated whitespace.
The empirical evaluations of Fusion-in-Decoder for open domain QA are presented and following benchmark datasets are used:
- NaturalQuestions
- This contains questions corresponding to Google search queries.
- TriviaQA
- Contains questions gathered from trivia and quiz-league websites. The unfiltered version of TriviaQA is used for open-domain question answering.
- SQuAD v1.1
- It is a reading comprehension dataset. Given a paragraph extracted from Wikipedia, annotators were asked to write questions for which the answer is span from the same paragraph.
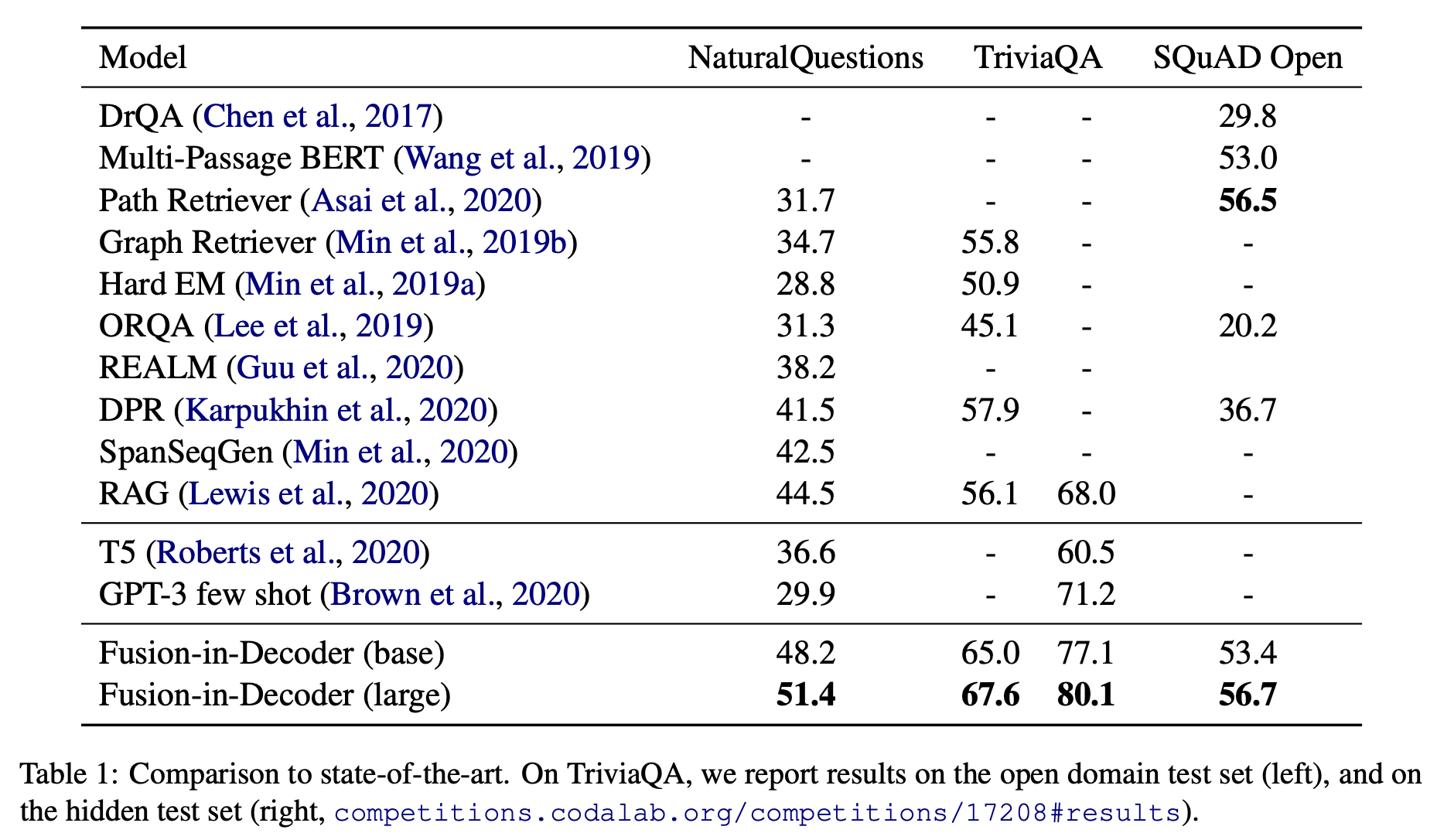
The table above shows the comparison of approach described in this paper with existing approaches for open-domain question answering. Key observations:
- This approach outperforms existing work on NaturalQuestions and TriviaQA benchmarks.
- Generative models seem to perform well when evidence from multiple passages need to be aggregated, comparaed to extractive appraoches.
- Using additional knowledge in generative models by using retrieval lead to important performance gains.
- On NaturalQuestions, the closed book T5 model obtains 36.6% accuracy with 11B parameters, whereas this approach obtains 44.1% with 770M parameters plus Wikipedia with BM25 retrieval.
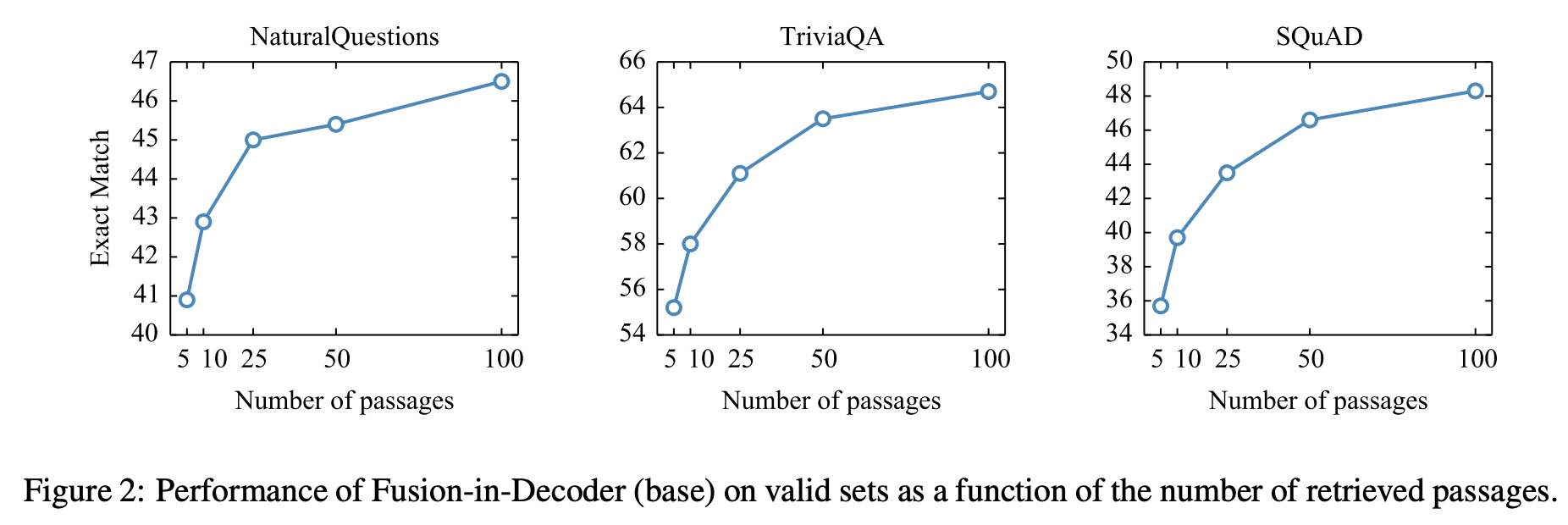
The figure above shows the performance of this approach with respect to the number of retrieved passages. Specifically, on increasing the number of passages retrieved from 10 to 100 leads to 6% improvement on TriviaQA and 3.5% improvement on NaturalQuestions. As compared to other extractive models whose performance peak around 10 to 20 passages. This is used as an evidence by Authors that sequence-to-sequence models are good at combining infomration from multiple passages.