Transformer Feed Forward layers are Key-Value memories
15th Aug 2021
keywords: language modeling, transformers, feed-forward, key-value memories
In this post I will be sharing some interesting empirical observations from Transformer Feed-Forward Layers Are Key-Value Memories by (Geva et al. 2020)
TL;DR
- This paper provides insights into what actually is stored in two-thirds of a transformer model's parameter. i.e. Feed-forward layers.
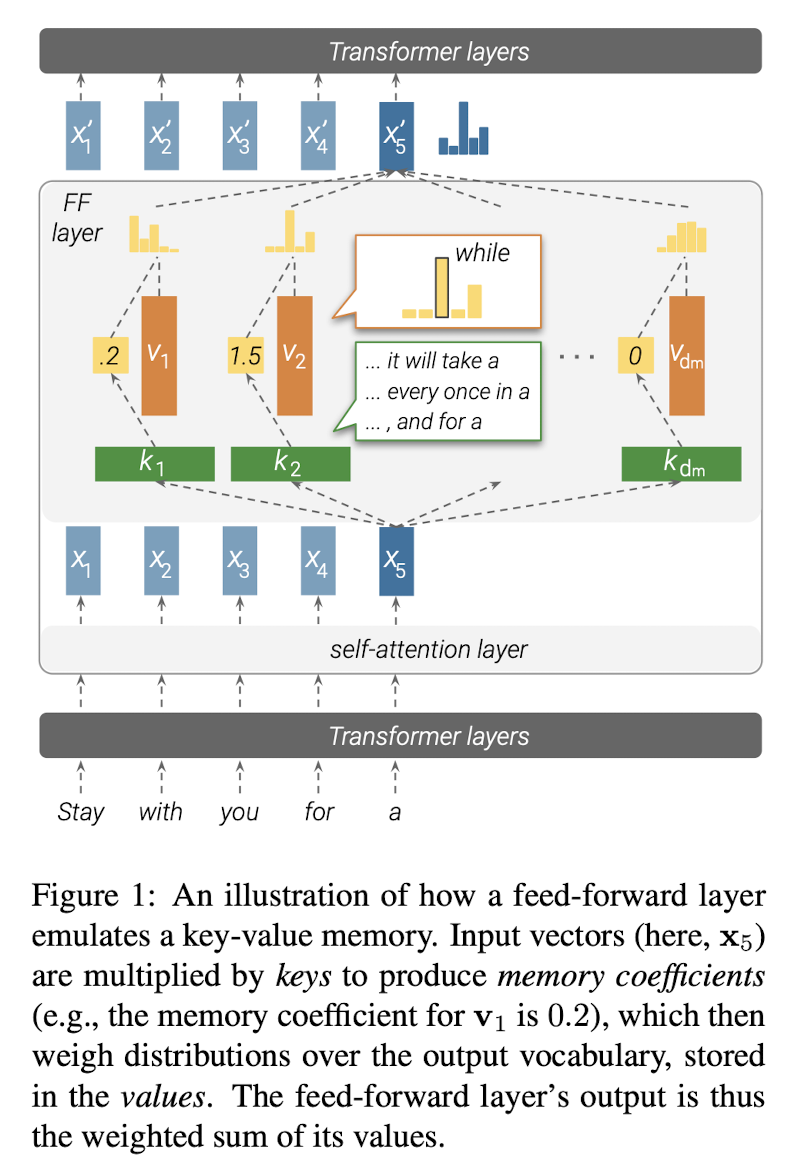
- Through empirical observations, authors show that transformer feed-forward layers operate as key-value memories, where key correlates to textual patterns in training instances and value induces a distribution over output vocab indicating what token is most likely to appear after the textual pattern.
- Lower Feed-forward layers tend to capture shallow textual patterns such as n-grams whereas upper Feed-forward layers capture semantic patterns indicated by variations in textual patterns denoting the same semantic concept.
- While there is much literature to attributing success of Transformer models to self-attention layers, the role of feed-forward layers is yet being explored and this paper is one such contribution.